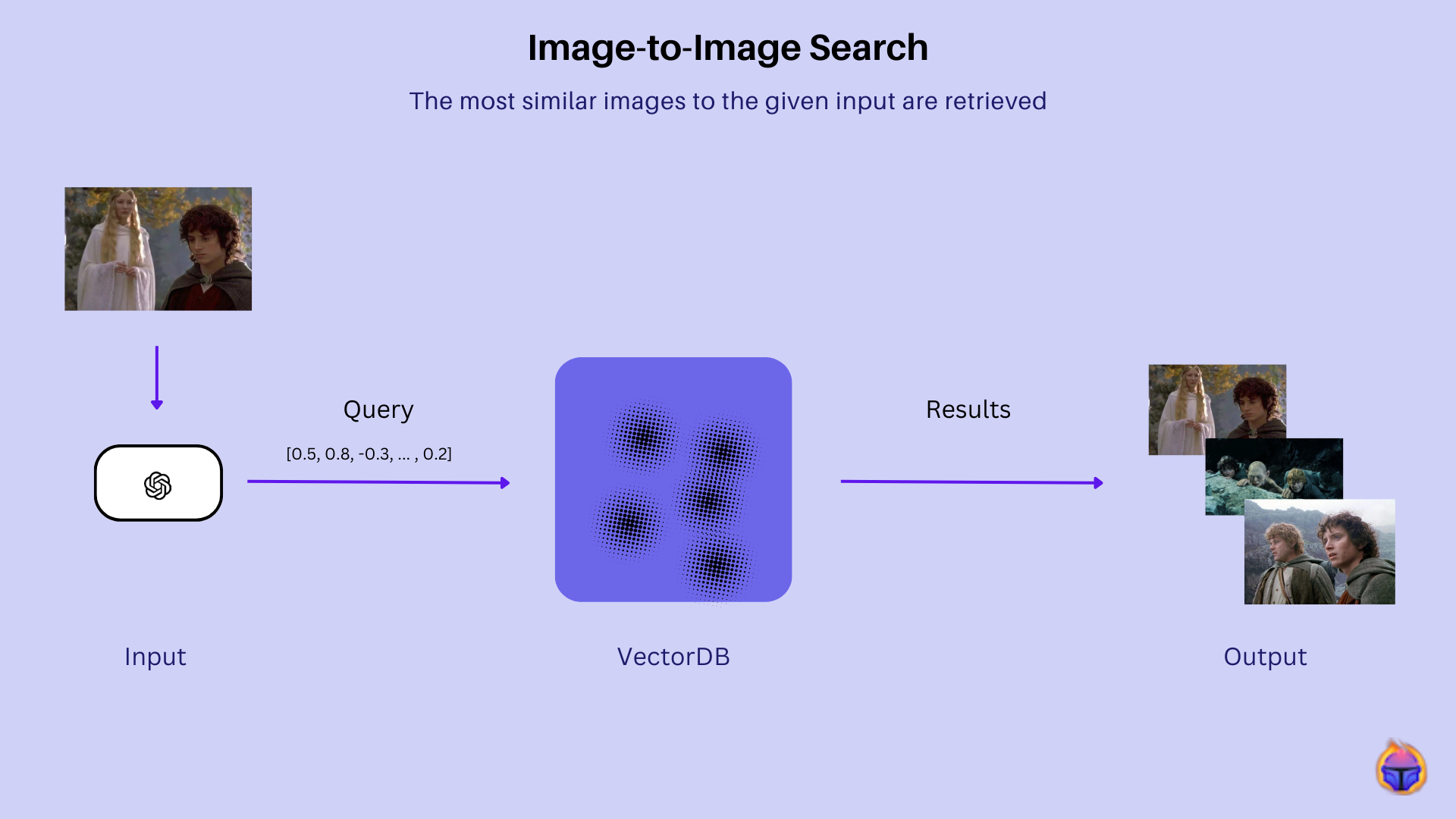
In this article we walk you through the process of building an Image-to-Image search tool from scratch!
By the end of this post you will learn by doing why Image-to-Image search is a powerful tool that can help you find similar images in a vector database.
Table of Contents
- Image-to-Image Search
- CLIP & VectorDBs: in brief
- Building an image-to-image search tool
- Time for testing: The Lord of The Rings
- Wait, what can I do if I have 1M or even 100M images?
1. Image-to-Image Search
What do we mean by Image-to-Image Search?
In traditional image search engines, you typically use text queries to find images, and the search engine returns results based on keywords associated with those images. On the other hand, in Image-to-Image search, you start with an image as a query and the system retrieves images that visually resemble the query image.
Imagine you have a painting, like a beautiful picture of a sunset. Now, you want to find other paintings that look just like it, but you can’t use words to describe it. Instead, you show the computer your painting, and it goes through all the paintings it knows and finds ones that are very similar, even if they have different names or descriptions. Image-to-Image Search, ELI5.
What can I do with this search tool?
An image-to-image search engine opens up exciting possibilities:
- Finding specific data — Search for images that contain specific objects you want to train a model to recognize.
- Error analysis — When a model misclassifies an object, search for visually similar images it also fails on.
- Model debugging — Surface other images that contain attributes or defects that cause unwanted model behavior.
2. CLIP and VectorDBs: in brief
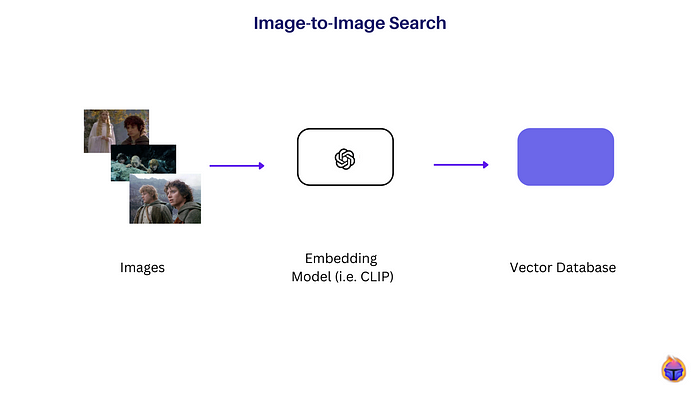
Figure 1 shows the steps to index a dataset of images in a vector database.
- Step 1: Gathering a dataset of images (can be raw/unlabelled images).
- Step 2: CLIP [1], an embedding model, is used to extract a high-dimensional vector representation of an image that captures its semantic and perceptual features.
- Step 3: These images are encoded into an embedding space, where embeddings (of the images) are indexed in a vector database like Redis or Milvus.
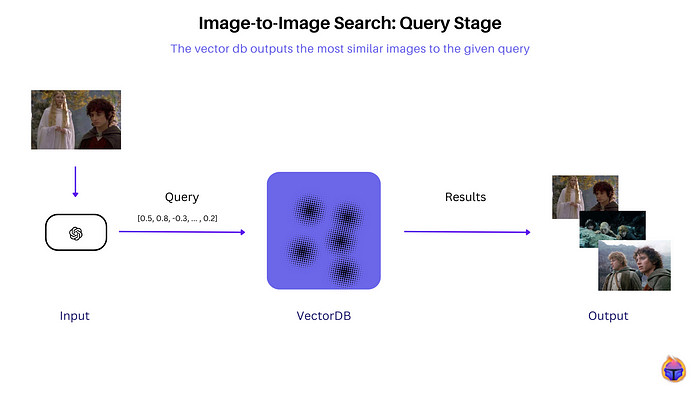
At query time, Figure 2, a sample image is passed through the same CLIP encoder to obtain its embedding. A vector similarity search is performed to efficiently find the top k nearest database image vectors. Images with the highest similarity score to the given query are returned as the most visually similar search results.
Cosine similarity is the most used similarity metric in VectorDB applications:
Cosine Similarity is a measure of similarity between two non-zero vectors defined in an inner product space.
Cosine similarity is the cosine of the angle between the vectors; that is, it is the dot product of the vectors divided by the product of their lengths. It follows that the cosine similarity does not depend on the magnitudes of the vectors, but only on their angle. [3]
At query time, Figure 2, a sample image is passed through the same CLIP encoder to obtain its embedding. A vector similarity search is performed to efficiently find the top k nearest database image vectors. Images with the highest cosine similarity scores to the query embedding are returned as the most visually similar search results.
3. Building an image-to-image search engine
3.1 Dataset — The Lord of The Rings
We use Google Search to query images related to the keyword: “the lord of the rings film scenes”. Building on top of this code, we create a function to retrieve 100 urls based on the given query.
3.2 Obtaining embedding vectors with CLIP
🗒 Note: Find all the libraries and helper functions to run the code in this Colab notebook.
Extracting all the embeddings for our set of images.
97 out of 100 urls contain a valid image.
3.3. Storing our embeddings in Pinecone
For this article, we’ll use Pinecone as an example of a VectorDB, but you may use a variety of other VectorDB’s providers, such as: QDrant, Milvus, Mongo, or Redis.
🔍 You can find a nice comparison of these vector database services on our article on VectorDBs.
To store our embeddings in Pinecone [2], you first need to create a Pinecone account. After that, create an index with the name “image-to-image”.
Create a function to store your data in your Pinecone index.
Run the above function to obtain:
3.4 Testing our image-to-image search tool


Figure 4 shows the results obtained by our Image-to-Image search tool. All of them depict at least two characters walking in an open background. resembling a landscape. Specifically, the sample with ID 47 attains the highest similarity score, 1.0. This is no surprise, as our dataset includes the original image used in the query (Figure 3). The next most similar samples are a tie: both ID 63 and ID 30 each have a score of 0.77.
5. Wait, what if have 1 Million images or even 100 Million images?
As you might have realized, building a tool to do image-to-image search by querying some images from Google Search is fun. But, what if you actually have a dataset of 100M+ images? 🤔
In this case you are likely to build a system rather than a tool. Setting up a scalable system is not an easy feat though. Also, there are a number of costs involved (e.g., storage costs, maintenance, writing the actual code).
For these scenarios, at Tenyks we have built a best-in class Image-to-Image search engine that can help you perform multi-modal queries in seconds, even if you have 1 Million images or more!
Our system also supports text and object-level search! Try our free sandbox account here.
References
[1] CLIP
[2] Text-to-image and image-to-image Pinecone
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan
If you would like to know more about Tenyks, sign up for a sandbox account.