.png)
Artificial intelligence has enabled rapid progress in autonomous driving, but achieving fully driverless vehicles remains an elusive goal. With plenty of workshops dedicated to autonomous driving topics, CVPR 2023 offered us invaluable insights into the complexities of real-world Autonomous Vehicles (AV) deployment. By engaging with top researchers and engineers tackling these challenges head-on, we gained a deeper understanding of the hidden hurdles in AV.
Going beyond the algorithms and models, we explore how massive amounts of high-quality data are crucial to solving complex, real-world problems like navigating chaotic city traffic or identifying and responding to emergency vehicles. Mastering these challenges key to unlocking the promise of self-driving cars.
Table of Contents
- Autonomous Driving’s main insight from CVPR 2023
- Safety-Critical Edge Cases
- Domain Generalization
- Simulated Data
- Multi-modal Sensors and Sensor Fusion
- Dynamic Scenes
- Tenyks: Finding edge cases
- Summary
1. Autonomous Driving’s main insight from CVPR 2023
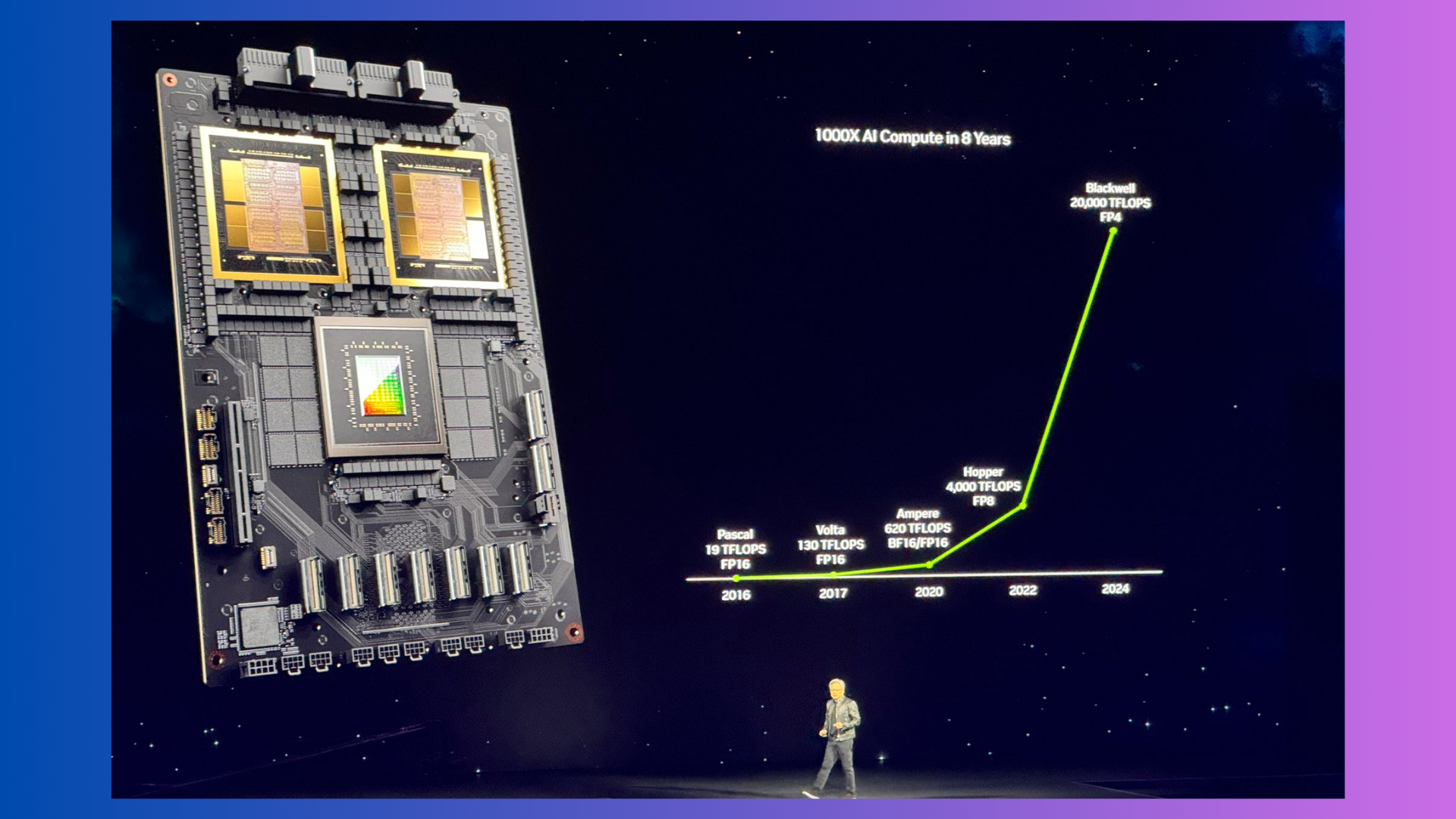
At CVPR 2023, the world’s premier event for computer vision and pattern recognition, autonomous vehicles stole the show. With numerous workshops and tutorials dedicated solely to exploring autonomous vehicles in-depth, coupled with scores of accepted papers on the topic, the enthusiasm for this groundbreaking technology was palpable among researchers and companies alike.
During our time mingling with leading experts at CVPR 2023, a clear theme emerged in our conversations with representatives from companies like Tesla, Waymo, Zoox, Waabi, Toyota, and Hyundai: data is king. These insightful discussions provided a glimpse into the current triumphs and tribulations of building autonomous vehicles. While many challenges remain, one message rang loud and clear — high-quality data is the fuel that will power autonomous vehicles into the mainstream.
Cutting-edge self-driving cars depend on huge amounts of data to see, understand, and navigate our complex world. However, the current technology struggles with a number of data-related problems that block its path to widespread use and continued progress. In the following sections, we explore where autonomous vehicles and data intersect, exposing what’s needed to unlock the awe-inspiring potential of this revolutionary technology.
2. Safety-Critical Edge Cases

For self-driving cars to earn a spot in our daily lives, safety is non-negotiable. Automakers and riders expect autonomous vehicles make safety the top priority,especially in worst-case scenarios anywhere at any time.
In autonomous vehicles, “edge cases” refer to rare, unexpected events outside normal driving. These wild cards could be anything from a fallen tree branch to a strange move by someone on foot or bike to an animal darting into traffic. Their diversity and complexity present a massive challenge. Self-driving vehicles must quickly yet accurately read these situations and make split-second decisions guaranteeing safety inside and outside the vehicle.
For driver assistance, nominal driving matters most. For driverless autonomy, edge cases behaviour matters most. — Kodiak Robotics at CVPR 2023
These wild cards could be anything from a fallen tree branch to a strange move by someone on foot or bike to an animal darting into traffic. Their diversity and complexity present a massive challenge. Self-driving vehicles must quickly yet accurately read these situations and make split-second decisions guaranteeing safety inside and outside the vehicle.
Handling edge cases requires a robust data strategy. Autonomous systems must experience or encounter events like these during training. As illustrated on Figure 1, this demands huge data volumes and smart collection methods.
Gathering edge case data has obstacles. Some scenarios may never happen naturally. Companies use simulation tools to generate synthetic data mimicking rare situations. Also vital is data-sharing between companies and groups, to amass diverse data capturing edge cases across the board.
Collecting diverse, high-quality data and enhancing safety for unpredictable edge cases will shape autonomous vehicles’ future and adoption. With creative data solutions and unwavering safety focus, self-driving cars can navigate the road ahead.
3. Domain Generalization

A related issue to edge cases in autonomous vehicle development from a data-centric lens is Domain Generalization (DG), “Domain generalization aims to achieve OOD generalization by using only source data for model learning” [1]. This refers to the ability of an autonomous system to operate in new environments different from its training.
Consider this: an autonomous vehicle trained on one domain (Paris) but needs to generalize to another (Sidney), see Figure 2. Even more challenging: a vehicle trained on San Francisco’s steep hills and trolley tracks may struggle in New York’s grid system.
To tackle this issue, domain adaptation strategies are employed [2]. “Domain adaptation is a sub-field within machine learning that aims to cope with these types of problems by aligning the disparity between domains such that the trained model can be generalized into the domain of interest.” [3].
Domain adaptation involves fine-tuning the model with data representative of the new environment, which allows the model to retain the knowledge it has gained from the original dataset while adapting to the nuances of the new environment. However this technique still requires substantial data from the new environment and is not robust to sudden shifts. To build a truly robust autonomous system, it is imperative that the model is trained on a highly diverse dataset from the get-go. This diverse dataset should encompass various driving environments, weather conditions, traffic patterns, and more. The idea is to make the model as versatile as possible so that it can generalize its learning across different domains without compromising on safety or efficiency.
By using a combination of domain adaptation strategies and diverse training datasets, it’s possible to create more versatile and reliable autonomous systems that can safely navigate an array of environments. This aspect is crucial in advancing autonomous vehicle technology and making it a viable transportation option worldwide.
4. Simulated Data

Simulated data is rising in autonomous vehicles, augmenting datasets (incorporating edge cases) with real-world data is challenging or infeasible. “Simulation has emerged as a potential solution for training and evaluating autonomous systems on challenging situations that are often difficult to collect in the real-world.” [4].
However, simulated data has pitfalls. One concern is hampering generalization of the system: simulated data must closely resemble real sensor data, critical for perception via Light Detection and Ranging (LIDAR) [5], radar, etc. Discrepancies may lead to decisions based on unrealistic data.
Moreover, simulations are constrained, unable to perfectly replicate real-world unpredictability. Subtle reflections, debris movements, pedestrian motions — incredibly complex to model accurately. Despite edge cases, simulations likely miss scenarios encountered in real life.
Simulated data is valuable but must be used judiciously. As shown in Figure 3, the ideal use-case combines simulation with diverse real-world data, enabling systems to learn and operate safely across environments.
5. Multi-modal Sensors and Sensor Fusion

Autonomous vehicles rely on sensors to perceive the world, but approaches vary. While some use only cameras, falling LIDAR costs have spurred a shift toward multiple modalities.
LIDAR impacts more than hardware. By using lasers to map surroundings, it generates vast 3D point clouds requiring unique data processing. Compared to cameras, bulk LIDAR and radar data collection brings new hurdles. These sensors also tend to be less reliable, with more noise and errors.
Sensor fusion is no small feat. Integrating camera visuals with LIDAR distances aims to create a comprehensive 3D view: “3D object detection, which intelligently predicts the locations, sizes, and categories of the critical 3D objects near an autonomous vehicle, is an important part of a perception system” [6]. But blending these complex, varied data streams requires sophisticated algorithms attuned to each sensor’s quirks.
Reliably collecting or simulating multi-modal sensor data remains challenging. Current methods struggle to capture intricate sensor interplay in bulk simulations. With deep learning models needing huge, trustworthy data sets, this is a key area for innovation. Figure 4 shows the components of a data pipeline for a perception system, starting from the sensors to the data intensive modules such as collection and processing.
While promising, multi-modal sensors introduce new data obstacles around collection, simulation, and fusion. Conquering these is pivotal for advancing autonomous vehicle tech safely.
6. Dynamic Scenes

Static scenes are straightforward — parked cars, buildings. But dynamic scenes require constantly evaluating moving objects — their trajectories, likely actions. Autonomous vehicles must predict motion.
Ideally objects move predictably. Reality is more erratic — sudden jaywalking, unsignaled lane changes. “Often the scanned scenes contain moving objects. Points on those objects are not correctly aligned by just undoing the scanner’s ego-motion.” [7]. These irregular movements make dynamic scenes especially tricky as illustrated in Figure 5.
Prediction requires understanding complex behavioural patterns and decision-making — highly unpredictable. To efficiently tackle this, autonomous vehicles need huge datasets on dynamic scenarios and advanced, sophisticated models to make sense of the data.
Dynamic scenes are a major challenge, demanding extensive, diverse data and intelligent modeling techniques to analyze the data and make reliable predictions. Optimizing motion prediction algorithms is essential for autonomous vehicle safety and efficiency in real-world driving.
In general, while static environments are simple, dynamic scenes introduce complex motion prediction problems. “Motion forecasting is a challenging problem due to the heterogeneity in the scene and the inherent uncertainties in the problem.” [8]. To handle unpredictable behaviours, autonomous vehicles need ample dynamic scenario data and sophisticated models to interpret it. Advances in motion forecasting are key to real-world readiness.
7. Tenyks: Finding edge cases
7.1 So, how does the “edge cases” challenge is often solved?
Despite advances, autonomous vehicles still struggle with rare but critical edge cases. While techniques like simulation and hazard detection systems seem promising for generating and identifying these unusual scenarios, each confront stubborn hurdles.
Limited data, validation troubles, poor generalization, heavy computation, and uninterpretable complexity plague current solutions. With sparse real-world examples, reliably training and evaluating obscure edge performance proves profoundly difficult. There is urgent need for creative and efficient solutions that consolidate data, enable meaningful validation and speed up the time to run experiments in machine learning pipelines.
When an autonomous car sees a new edge case, its brain kicks into overdrive trying to figure it out. But without diverse training data, the car struggles, its traction control failing like a street racer taking on Dominic Toretto (see Figure 6). To master edge cases, self-driving cars need furious amounts of data, or their performance will spin out.

7.2 Are the other alternatives?
At Tenyks we are building technology to serve as the perfect companion to boost ML Engineers’ productivity. You can find edge cases in record time with the Tenyks platform, in this section we show you one of the features to enhance your outliers hunt.
7.2.1 The dataset
Figure 7. Autonomous driving dataset generated by simulation
We used an autonomous driving dataset generated by simulation (hint: check Section 4 Simulated Data above), see Figure 7. This object detection dataset has 10 classes such as: bike, person, motorbike, vehicle, traffic_sign_30, traffic_light_green, and others.
7.2.2 Traffic signs edge cases
Figure 8. Identifying edge cases in traffic signs
The dataset includes classes describing traffic signs for different speed levels. Figure 8 shows how the class traffic_sign_60 is generally predicted correctly, but there are a few instances where it is mispredicted as traffic_sign_30.
Why could this be happening? A few practical reasons might include:
- Insufficient training data for classes traffic_sign_60 — the model might have seen far more examples of class traffic_sign_30 during training.
- Inter-class variation — the differences between class traffic_sign_60 and class traffic_sign_30 are difficult to discern from the source data (e.g. perhaps the simulation produces low fidelity samples for these classes).
While building this kind of functionality into your system is not rocket science — any ML Engineer should be capable of it — identifying these long-tail edge cases one by one, in a systematic way, can be quite annoying. That’s why the Tenyks platform has built all of this for you.
7.2.3 Is this a motorbike or a bike?
Figure 9. Edge cases: classes motorbike and bike
Another edge case in this dataset occurs when the model predicts an object as a bike when it’s actually a motorbike, or vice versa. Figure 9 shows how quickly you can identify these kinds of long-tail cases: the ability to click and obtain a number of these hard-to-see examples will surely translate into more time where you can truly add value for your customers.
The naive answer of why this edge case might be happening implies that bike and motorbike are very similar objects, however a more thoughtful analysis might include the next reasons:
- Visually similar shape and size — bicycles and motorbikes share a similar overall frame and two-wheeled structure that could be difficult for a model to reliably differentiate.
- Small dataset scale — If there are far fewer examples of motorbikes than standard bikes in the training data, the model may have insufficient motorbike understanding.
- Viewpoint limitations — If motorbikes are only seen from a limited set of viewpoints, the model may fail to recognize them in unfamiliar orientations.
The beauty of the Tenyks platform is not only that you can spot edge cases at lightning speed, but also that you can use additional tools like a multi-class confusion matrix, already built into the platform, to quickly test potential reasons like the ones described above. Simply with the multi-class confusion matrix, you can get information on the per-class number of training examples (i.e. perhaps the edge case class is underrepresented), total number of undetected objects, as well as other classes being falsely predicted as bike or motorbike.
7.2.4 Lighting conditions
Figure 10. Outliers with brightest lighting conditions
Another useful feature of the Tenyks platform is the embedding viewer, which enables you to quickly identify edge cases. Figure 10 illustrates how embeddings plots can rapidly reveal interesting clusters where outliers are likely to exist. The images with the brightest lighting conditions are located on the left, providing valuable insights when testing the robustness of your model under different lighting conditions.
8. Conclusion
The landscape of autonomous vehicles is complex and ever-evolving, underpinned by a robust foundation of data. The sheer diversity and volume of data required for these systems to function effectively is staggering, covering an expansive range of scenarios, environments, and sensor modalities. Making sense of this data and turning it into actionable insights is a monumental task, demanding advanced algorithms, large-scale simulations, and sophisticated machine learning techniques.
Our exploration of the data-centric perspective on autonomous vehicles has shed light on a number of crucial challenges. Edge cases, domain generalization, the use of simulated data, multimodal sensor fusion, and the dynamic nature of real-world environments each pose significant hurdles that must be overcome. Each challenge underscores the inescapable fact, as we heard it first hand at CVPR, that achieving fully autonomous driving is as much a data problem as it is a technological one.
Nevertheless, each challenge also presents an opportunity. The potential benefits of overcoming these obstacles — from safer roads to reduced traffic congestion and improved accessibility — are enormous. By innovating upon new data collection and simulation techniques, we can unlock the promise of autonomous vehicles and develop systems that are safe, efficient, and universally reliable.
It’s clear that the road to fully autonomous vehicles is steeped in data. Every mile driven, every sensor ping, and every simulated scenario brings us one step closer to that future. We at Tenyks look forward to continuing this journey and contributing to the unfolding story of autonomous vehicles — a story that is written in the language of data.
References
[1] Domain Generalization: A Survey
[2] Deep Unsupervised Domain Adaptation: A Review of Recent Advances and Perspectives
[3] A Brief Review of Domain Adaptation
[4] Learning Robust Control Policies for End-to-End Autonomous Driving from Data-Driven Simulation
[5] Lidar for Autonomous Driving: The principles, challenges, and trends for automotive lidar and perception systems
[6] 3D Object Detection for Autonomous Driving: A Comprehensive Survey
[7] Dynamic 3D Scene Analysis by Point Cloud Accumulation
[8] Improving Motion Forecasting for Autonomous Driving with the Cycle Consistency Loss
Authors: Jose Gabriel Islas Montero, Dmitry Kazhdan, Shea Cardozo
If you would like to know more about Tenyks, sign up for a sandbox account.